Neste exemplo, veremos como fazer query em arquivos JSON armazenados em um data lake no S3. Em um data lake é normal ter arquivos dos mais variados tipos, como CSVs, JSONs, etc. Com algumas ferramentas podemos extrair informações desses arquivos, usando SQL ANSI.
Primeiramente, vou falar um pouco sobre as ferramentas que utilizaremos. Depois, com Python, extrairemos os dados de uma API, subiremos no bucket e partiremos para a demonstração hands-on.
Os serviços
AWS Athena
- É um serviço baseado no famoso Presto, criado pelo Facebook.
- O Presto desacopla a camada de dados, ou seja, os dados não estarão no Presto em si.
- Você paga por query: $5 por cada TB de dados escaneado.
- Os resultsets, por padrão, ficam armazenados em um bucket no S3 por 45 dias.
AWS Glue
- Dados armazenados em um bucket são apenas dados.
- Para que possamos consultá-los através do Athena, precisaremos de metadados.
- O Glue, através dos crawlers, consegue saber o esquema desses dados e armazenar esses esquemas no Glue Data Catalog.
- Esse que vamos utilizar (Data Catalog) é apenas um dos recursos do Glue, que é muito poderoso.
- O AWS Glue, por exemplo, pode gerar automaticamente scripts de ETL em Scala ou PySpark e rodar esses scripts através de jobs sem você precisar gerenciar um ambiente Spark.
O dataset
Agora que já sabemos o mínimo sobre os serviços que utilizaremos, vamos buscar um dataset para que possamos analisar. Para isso, eu extraí, através de uma API, todas as partidas do campeonato brasileiro de 2019 (saudades do futebol né, meu filho). Segue o script Python que criei. Desta forma já extraio os dados e subo para meu bucket no S3, utilizando a biblioteca boto3.
import requests
import json
import os
import boto3
from botocore.exceptions import ClientError
# URL
url = "https://api.football-data.org/v2/"
# A chave da API é uma variável de ambiente do meu S.O.
api_key = os.environ.get('FOOTBALL_DATA_API_KEY')
# Configura headers
headers = {'X-Auth-Token': api_key}
def get_matches_from_competition(competition_id, filter=''):
response = requests.get(
url + 'competitions/' + competition_id + '/matches?' + filter,
headers=headers
)
if response.status_code != 200:
raise (requests.HTTPError)
return response.json()['matches']
def upload_file(file_name, bucket, object_name=None):
s3_client = boto3.client('s3')
try:
s3_client.upload_file(file_name, bucket, object_name)
except ClientError as e:
logging.error(e)
return False
return True
campeonato_brasileiro = 'BSA'
json_matches = get_matches_from_competition(
competition_id=campeonato_brasileiro,
filter='season=2019'
)
with open('partidas.json', 'w', encoding="utf8") as json_file:
for item in json_matches:
json.dump(item, json_file, separators=(',', ':'), ensure_ascii=False)
json_file.write('\n')
upload_file('partidas.json', 'fcl-raw-data-lake', 'brasileirao-2019/dataset/partidas.json')
Classifiers
Para que o crawler identifique o esquema dos seus dados, você pode adicionar “classifiers“. Por exemplo, imagine que eu precise:
- Ler somente uma chave específica de cada JSON, ou
- Dizer que o separador do meu arquivo CSV é um ‘;’ ou
- Desconsiderar o primeiro nível do meu JSON
Hands-on
Agora que nosso dataset está no S3, vamos até o AWS Glue. No console, procuraremos a opção Crawlers e, obviamente, clicaremos na opção “New Crawler” e nesta primeira tela, você verá que é possível escolher o classifier e adicioná-lo ao crawler. Entretanto eu não precisarei de um, só adicionarei um nome e vou para a próxima etapa.
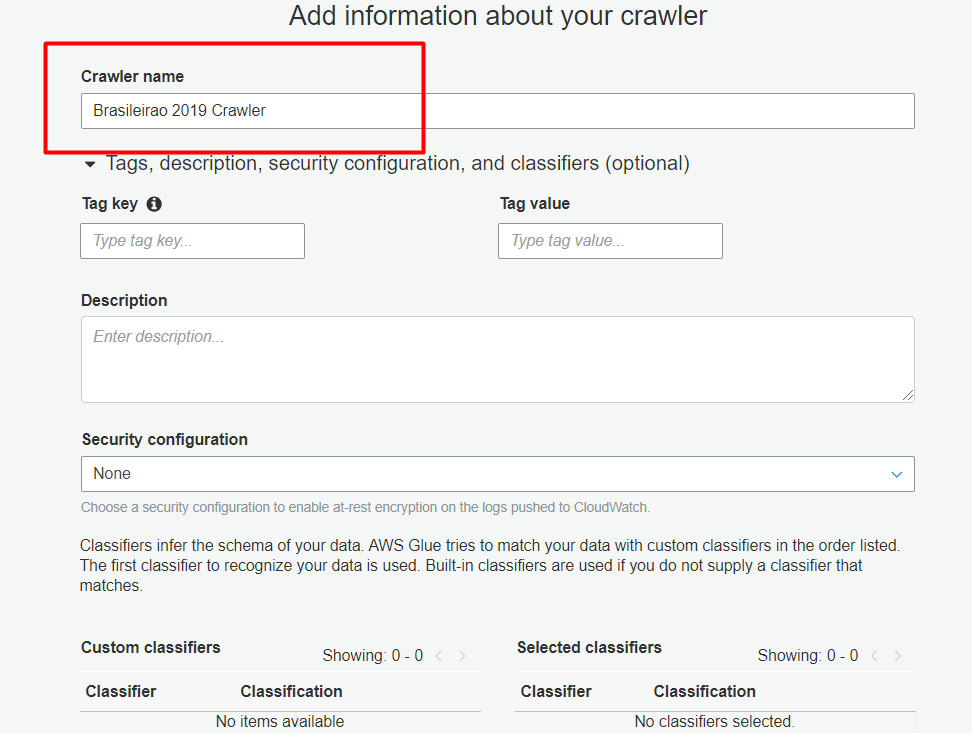
Aqui vamos selecionar o tipo da origem dos nossos dados, que no caso é o S3 (Data Stores):
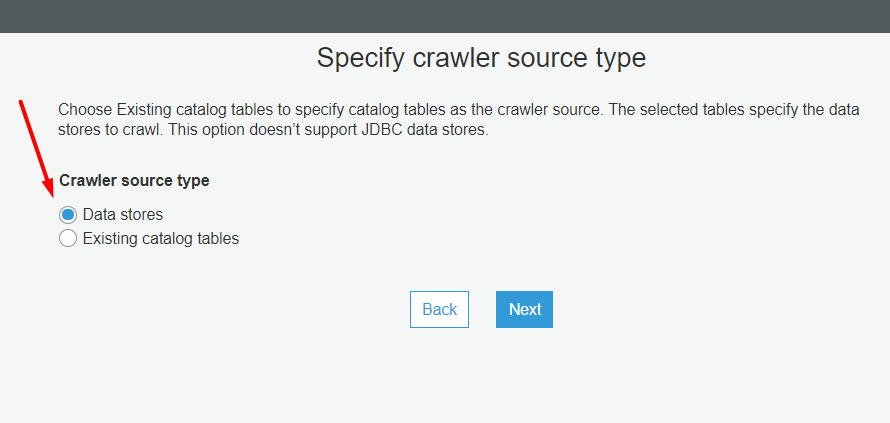
Selecione o Data Store (S3) e o caminho dos arquivos. Nesta opção, não selecione o arquivo em si (partidas.json), ou você não conseguirá fazer queries no Athena.
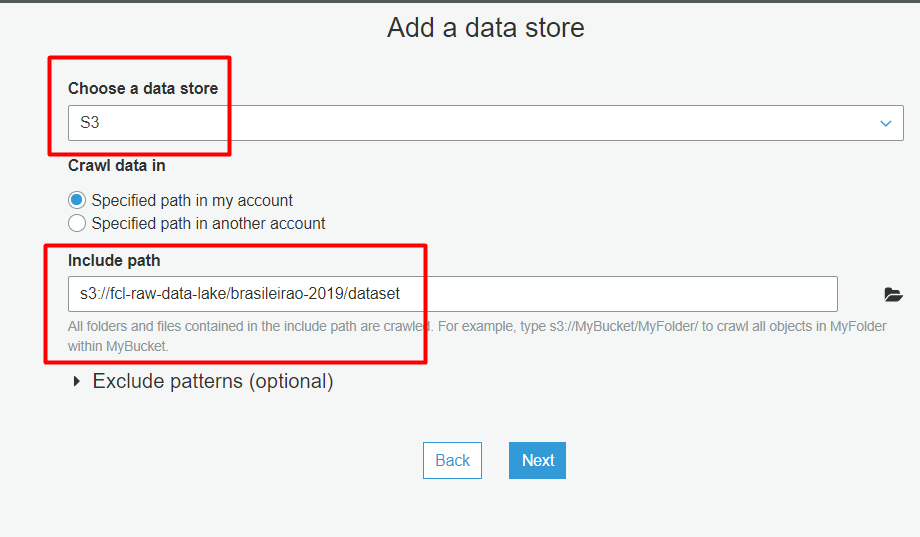
Não quero adicionar outro data store, e seguimos:
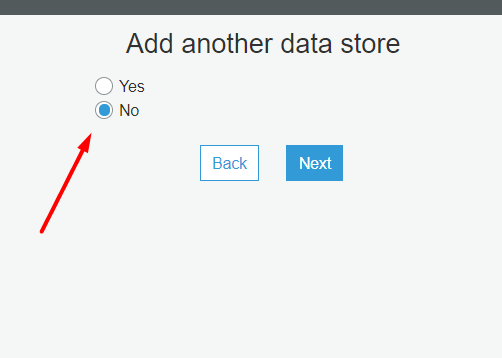
Aqui vamos criar uma IAM Role para que o crawler consiga acessar o S3:
Para a frequência, selecione “Run on demand” e siga em frente.
Aqui selecionaremos o banco de dados onde o crawler armazenará o esquema dos meus dados, além disso há algumas configurações opcionais relacionadas à atualização de esquemas ou deleção de dados no data store. Essas eu vou deixar no padrão.
Na tela final você confere os detalhes do seu crawler e clica em “Finish”.
Com o crawler criado, vamos rodá-lo. Em “Crawlers”, clique em “Run Crawler” (ah vá).

Clique em “Tables” e veja nos detalhes que ele pegou todos os campos do meu arquivo.

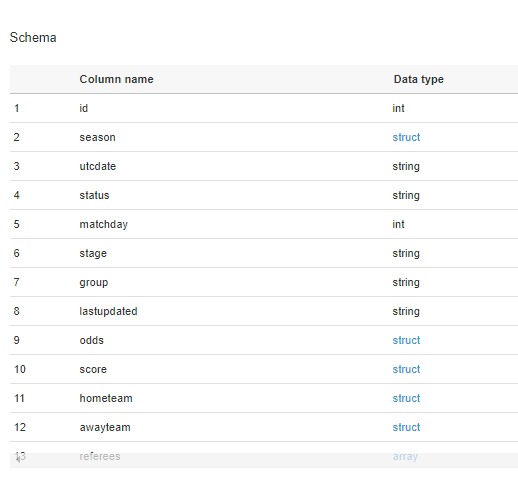
Perceba que há vários campos do tipo struct, e isso deve-se ao fato de que meu JSON tinha alguns objetos aninhados. Um exemplo do campo score, contido em cada partida:
"score":{
"winner":"HOME_TEAM",
"duration":"REGULAR",
"fullTime":{
"homeTeam":2,
"awayTeam":0
},
"halfTime":{
"homeTeam":1,
"awayTeam":0
},
"extraTime":{
"homeTeam":null,
"awayTeam":null
},
"penalties":{
"homeTeam":null,
"awayTeam":null
}
}
Como vou mostrar mais pra frente, isso não é um problema pro Athena, se eu quiser o número de gols do time visitante, por exemplo, basta referenciar o campo da seguinte forma: score.fulltime.awayteam
Indo para o Athena
No Athena, basta selecionar o nosso datasource, o banco de dados e começar a brincar. Que tal descobrir qual foi o recorde de gols em uma rodada?
SELECT SUM(score.fulltime.hometeam)+SUM(score.fulltime.awayteam) "Gols marcados", matchday as "Rodada" FROM "brasileirao"."dataset" GROUP BY 2 ORDER BY 1 DESC

E os times que marcaram mais gols em casa:
--- Mais gols marcados em casa. SELECT SUM(score.fulltime.hometeam) "Gols marcados em casa", hometeam.name as "Time" FROM "brasileirao"."dataset" GROUP BY 2 ORDER BY 1 DESC

Agora só depende da sua imaginação. E uma coisa bacana é que o Athena tem conectores ODBC, então você consegue conectar ferramentas compatíveis e extrair dados. Por exemplo, aqui criei um gráfico do Power BI mostrando a quantidade de gols por rodada.

Por hoje é isso, pessoal. Espero que tenham gostado do artigo, e caso tenham dúvidas ou sugestões fiquem à vontade para deixar um comentário.
