Aprenda a escolher corretamente a chave na hora de criar seu clustered index no SQL Server. Uma chave bem escolhida previne problemas.
Dentre os vários tipos de índice que temos no SQL Server, temos o índice clustered. No entanto, só podemos ter um índice clustered por tabela e ele contém todos os campos da sua tabela. Em outras palavras, um índice clustered é sua tabela no banco de dados. Não é “como se fosse sua tabela”. Se você tem um índice clustered, ele é sua tabela e por isso você só pode ter um.
É uma estrutura B-tree e tem uma chave que será usada para ordenação física dos dados. Apesar de as páginas serem ordenadas, as linhas dentro daquela página podem não estar ordenadas fisicamente. No entanto, com a ajuda do slot array – uma pequena estrutura no fim de cada página – o SQL Server sabe a ordem certa das linhas.
Os mitos
“A chave do seu índice clustered será sempre sua PRIMARY KEY”
ou
“A sua PK será sempre a chave do seu índice clustered.”
Isso são mitos.
Muita gente quando começa a estudar ou trabalhar com SQL Server, se depara com scripts de CREATE TABLE onde tem algo do tipo:
.. [Id] INT IDENTITY(1,1) PRIMARY KEY CLUSTERED
Ou
.. [Id] INT IDENTITY(1,1) PRIMARY KEY
Quando omitimos o tipo de índice que será usado na PRIMARY KEY, por trás dos panos o SQL Server cria um índice clustered. Mas e quando a palavra “CLUSTERED” tá lá? Ninguém sabe o porquê, mas ela está lá e ninguém mexe. “Aqui no meu ambiente de desenvolvimento tá funcionando mesmo, né? Show de bola.” E aquilo vai se repetindo de código em código. Até que dentre várias outras atrocidades, isso acontece na declaração de uma tabela:
.. [Id] UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY
Pronto, morreram 5 DBA’s em um universo paralelo. Dessa forma você estará usando um valor randômico para ordenar fisicamente seus dados. Isso vai causar page splits, fragmentação, entre outros problemas que vou demonstrar mais adiante. Não preciso nem comentar que o mesmo pode acontecer utilizando ORMs, como o famigerado Entity Framework.
Escolhendo a chave
O recomendado é que a chave do seu clustered index no SQL Server seja sequencial, curta, única e estática (que não se altere). Quando você cria um índice non-clustered, a chave do seu índice clustered será incluída nele, mesmo que você não explicite isso, para, por exemplo, fazer um key lookup. Essa é a operação de ir até sua tabela (índice clustered) e buscar os campos que não foram encontrados no seu índice non-clustered. O que ele usa pra fazer essa busca? A chave (key).
Por isso é recomendável que a chave seja curta, no sentido do tipo de dados utilizado. Um GUID por exemplo ocupa 16 bytes enquanto um INT ocupa 4 bytes e um BIGINT 8 bytes. Quando você pensa que essa chave será replicada para todos seus índices non-clustered e em cada índice poderemos ter milhões de registros, faz total sentido manter essa chave no menor tamanho possível.
Agora percebam o problema de performance que uma chave mal escolhida pode causar. Fiz 100 mil inserções com uma chave não sequencial, um UNIQUEIDENTIFIER, o que acontece é que a engine vai ter que “procurar” a página exata para guardar aquele valor no meio de um monte de páginas. Olha o problema. Nesse exemplo eu preferi iterar no T-SQL.
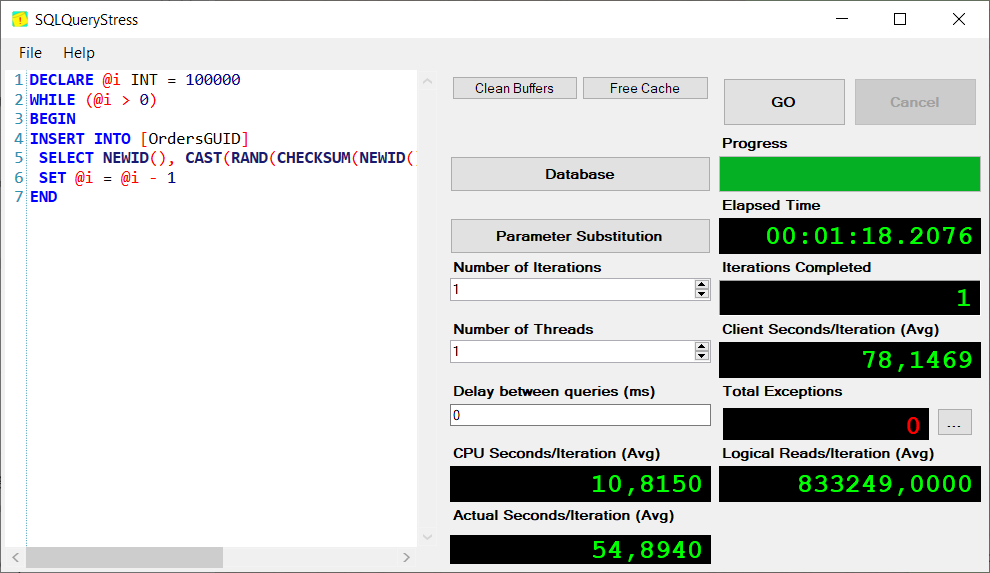
Agora com uma chave sequencial:
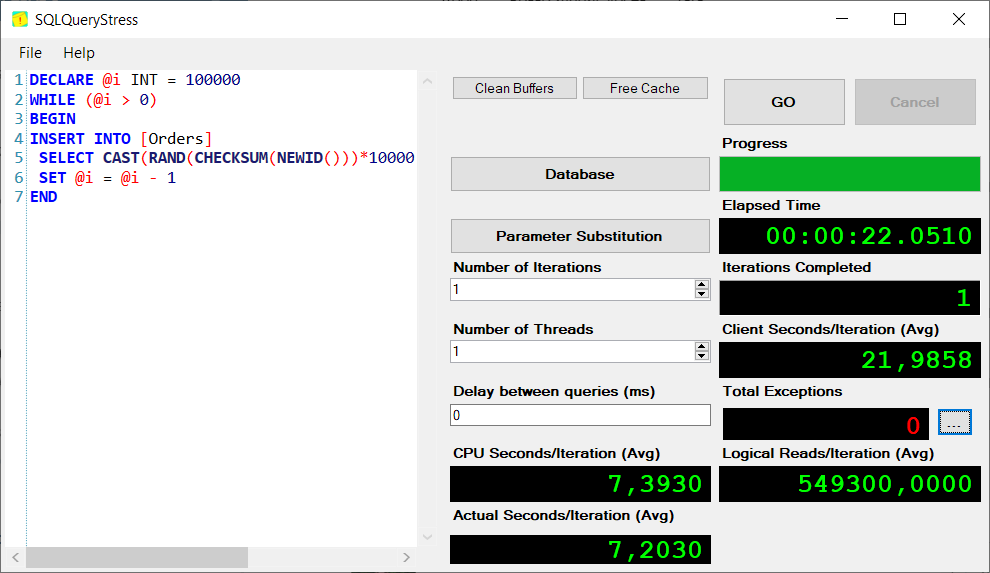
É raríssimo acontecer, mas uma chave sequencial pode levar à chamada “contenção na última página”, isso acontece quando várias threads tentam escrever na última página do índice e sofrem com o wait de PAGELATCH_*. Isso acontece em workloads muito específicos e você pode resolver utilizando in-memory ou particionamento. Na grande maioria dos workloads você se beneficiará de uma chave sequencial.
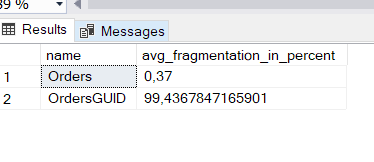
Legal, mas a escolha da chave do índice clustered influencia apenas na inserção dos dados? Não! Olhem a fragmentação das tabelas após essas inserções:
Eficiência na busca
Uma chave bem escolhida pode evitar até que você tenha que criar um índice non-clustered grande para atender à consultas que busquem uma faixa (range) de valores. Por exemplo, aqui eu crio uma tabela que possui um identity e um campo de data, que representa a data de inserção daquele registro:
CREATE TABLE [dbo].[Log] ( [Id] INT IDENTITY(1,1) PRIMARY KEY NOT NULL, [Hostname] VARCHAR(50) NOT NULL, [Username] VARCHAR(50) NOT NULL, [Message] CHAR(100), [CreateDate] DATETIME2 NOT NULL DEFAULT GETDATE() ) -- Tabela criada, inseri alguns registros e fiz uma query buscando por faixa de datas. SELECT [Id], -- Primary key da tabela, é sequencial. [Hostname], [Username], [Message], [CreateDate] FROM [Log] WHERE [CreateDate] BETWEEN '2019-10-22 20:05:50.1933333' AND '2019-10-22 20:11:04.3933333' OPTION (MAXDOP 1, RECOMPILE)
Vejam o plano de execução. Há a sugestão da criação de um índice no campo [CreateDate] incluindo todos os campos do SELECT (no nível folha, no entanto). Além disso, reparem que a recomendação não pede o campo [Id] pois como falei antes, por ser a chave do meu índice clustered, ele estará automaticamente incluído em qualquer índice non-clustered que eu criar na tabela.
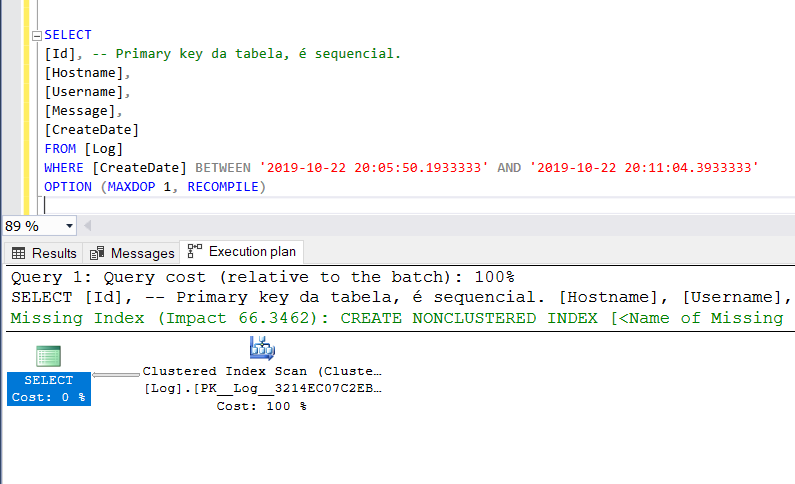
-- Missing Index
CREATE NONCLUSTERED INDEX [IX_CreateDate]
ON [dbo].[Log] ([CreateDate])
INCLUDE ([Hostname],[Username],[Message])Agora vou excluir a PK e recriar o índice clustered com chave nas colunas [CreateDate] e [Id], especificando a palavra UNIQUE (vou mostrar o porquê disso mais adiante).
ALTER TABLE [Log] DROP CONSTRAINT PK__Log__3214EC07C2EB2109
CREATE UNIQUE CLUSTERED INDEX IX_CL_Log ON [dbo].[Log] ([CreateDate], [Id])
ALTER TABLE [Log] ADD CONSTRAINT PK__Log__3214EC07C2EB2109 PRIMARY KEY (Id)Executei a query novamente e olhem o plano de execução:
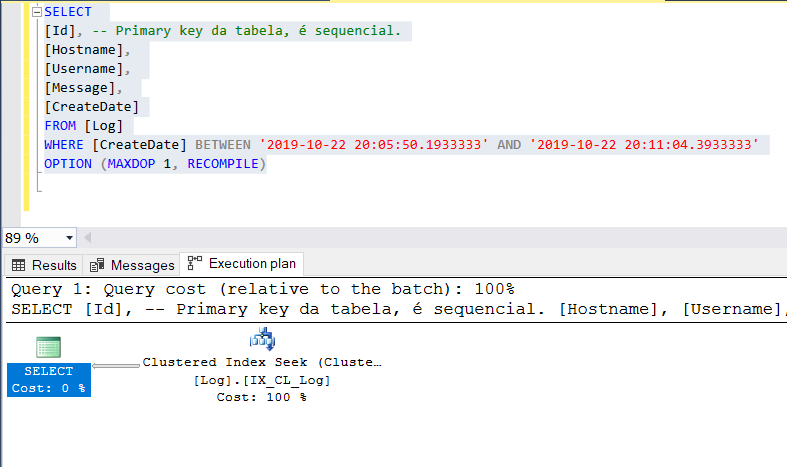
O operador muda para um Clustered Index Seek, muito mais eficiente. Ter deixado o índice clustered na coluna [Id] e ter criado um non-clustered na coluna [CreateDate], como o SQL Server sugeriu, teria funcionado? Sim. No entanto, você teria um índice non-clustered grande (com vários campos) que ocuparia muito espaço e haveria muito mais impacto a cada inserção de dados.
Unicidade é a chave
No exemplo acima, eu especifiquei a palavra UNIQUE na criação do clustered index. Contudo, quando não especificamos essa cláusula, em cada chave duplicada o SQL Server adiciona um “uniquifier” – um valor INT (4 bytes) – garantindo que aquela chave será única.
Fiz a seguinte consulta utilizando a função INDEXPROPERTY, verificando a propriedade não documentada ‘keycnt80‘. Como resultado, teremos a quantidade de campos usada na chave de um índice.
CREATE UNIQUE CLUSTERED INDEX IX_CL_Log ON [dbo].[Log] ([CreateDate], [Id])
SELECT key_cnt = INDEXPROPERTY(object_id, name, 'keycnt80') from sys.indexes WHERE name = 'IX_CL_Log'
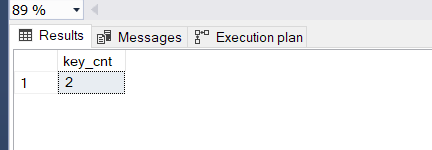
Somente os campos que declarei estão sendo utilizados na chave. Agora vamos ver o resultado dessa mesma consulta caso tenhamos uma chave que não seja declarada como única. Para isso executei o seguinte script:
-- Remove a PK
ALTER TABLE [Log] DROP CONSTRAINT PK__Log__3214EC07C2EB2109
-- Remove o índice clustered
DROP INDEX IX_CL_Log ON [dbo].[Log]
-- Recria o índice clustered sem a palavra UNIQUE
CREATE CLUSTERED INDEX IX_CL_Log ON [dbo].[Log] ([CreateDate], [Id])
-- Recria a PK
ALTER TABLE [Log] ADD CONSTRAINT PK__Log__3214EC07C2EB2109 PRIMARY KEY (Id)
-- Consulta do tamanho da chave
SELECT
key_cnt = INDEXPROPERTY(object_id, name, 'keycnt80') from sys.indexes
WHERE name = 'IX_CL_Log'
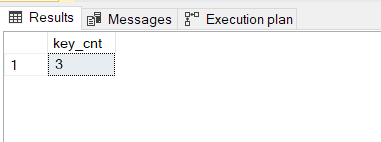
Apesar de eu ter declarado 2 campos na chave, foi adicionado o campo INT para fazer a unificação e agora (por baixo dos panos) minha chave possui 3 campos.
Conclusão
Neste post vimos a importância da escolha correta da chave do seu clustered index no SQL Server e como ela pode impactar em diversos aspectos do seu banco de dados. Uma chave bem escolhida pode previnir diversos problemas futuros.
Referências: https://docs.microsoft.com/pt-br/sql/relational-databases/sql-server-index-design-guide?view=sql-server-ver15